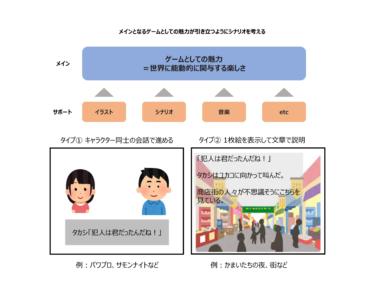
シナリオを書くときの悩み
自分の書いたシナリオを読み返してみると、「あれ?やたら同じ表現ばっかり使ってるなあ」と思うことがあるんですよね。
とくに今も使った「思う」という表現はやたら使ってしまいます。
同じ表現が連続して続くと、なんだかワンパターンな印象を受けるので、適宜言い換える必要があります。
たとえば「思う」を類語辞典で調べると「決意する」「思案する」「予測する」「訝しむ」「勘付く」「望む」など、様々な表現が出てきます。
これらの表現は「思う」だけでは感じ取りにくい微妙なニュアンスが付加されています。
つまり、連発している「思う」という言葉を、場面にあった別の表現に言い換えることで、「思う」だけでは伝えきれない情報を読者に提示することができ、文章に深みが増してきます。
でも自分が書いた文章って、自分の無意識の癖みたいなものがあるので、なかなか「同じ表現を使っている」ということにすら気づけなかったりするんですよね。
そこでひとつアイディアを閃いたのです。
テキスト解析すればいいじゃん、と。

(素材がないので糞みたいな画力で代替)
まずは自分の書いた文章を用意する
まずは作っちゃうおじさん(@hothukurou)に依頼して、ブラウザゲーム「逃げる僕たちと暗黒の森」のシナリオのテキストデータを全部ぶっこ抜いてもらいました。
「逃げる僕たちと暗黒の森」 シナリオ作成:私(中野 藤右衛門)

これでプログラム用の命令などが全消去された、生のテキストデータが入手できました。
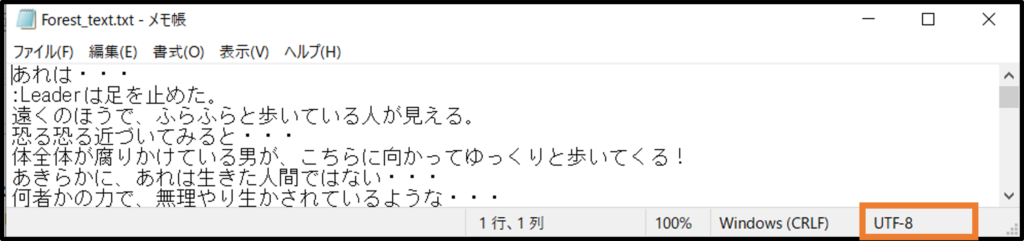
右下を見ると文字コードがUTF-8となっていますね。
これからやるテキスト解析では、文字コードはShift-JISでなければならないので、まずはメモ帳から文字コードを変換してあげます。
メモ帳から「名前を付けて保存」をするときに、文字コードを「ANSI」に変えるだけでOKです。

テキスト解析ツールを用意する(R、MeCab)
僕は普段、統計学用プログラミング言語の「R」を使うことが多いので、Rで分析していきます。
ただ、要はテキスト解析ができればいいので、ツールは何でもいいです。
たぶんプログラムを書かなくても、テキストを入れれば解析してくれるようなWEBサービスなんかはいろいろあると思うので、Rを使わない人は下の「テキスト解析の結果」まで飛んじゃってください。(そもそもこの章を読む人いるのか・・・?)
MeCab(めかぶ)は日本語のテキスト解析システムです。このシステムをRというプログラミング言語を使って操作していくわけですね。(めかぶはシステム製作者さんの好物とのこと)
僕はwindowsなのでまずはこのMeCabのサイトから「Binary package for MS-Windows」をダウンロードしました。
あとはRstudioを立ち上げて、「RMeCab」パッケージをRからインストールすれば完了です。
テキスト解析結果をグラフィカルに表示する「wordcloud2」パッケージも併せてインストールすると良いと思います。
テキストデータを解析していく
まずはRにテキストデータを読み込ませ、単語の登場数を数えましょう。
僕はプログラマーではないので、本職が見たら発狂するような書き方をしてるかもしれません。見逃してください。
#分析に必要なパッケージを読み込む
library(tidyverse)
library(RMeCab)
library(wordcloud2)
#Shift-Jisのテキストコードを読み込んで、単語の登場数を計算
forest_data <- RMeCabFreq("Forest_text_shift_jis.txt")次に名詞だけを抜き出してみましょう。
#名詞だけを抜き出す&よく出る順に並び替え----
forest_meishi <- forest_data %>%
filter(Info1 == "名詞") %>%
select(Term,Freq) %>%
arrange(desc(Freq))
#中身を確認
forest_meishi %>% View()すると下記のように使われた回数の多い名詞がリストアップできます。
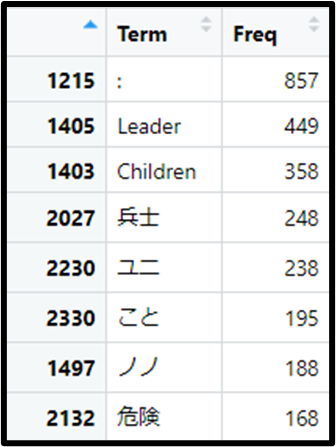
「Leader」や「Children」という単語が多いですね。
これはゲーム「逃げる僕たちと暗黒の森」の特殊な仕様です。
「逃げる僕たちと暗黒の森」は、子供たち六人がいろいろな選択肢を判断していくというゲームですが、そのときに子供たちのリーダー(最年長者)の名前だけ表示したい、みたいなシーンが出てくるんですね。
たとえば「:Leaderは〇〇した」と書いておくと、プログラムが自動的に現在のリーダーキャラの名前を抽出して、「ノノは〇〇した」とか「クレは〇〇した」などというように特定のキャラ名に置き換わるわけです。
テキスト解析においてはあまり意味がないので、そういう単語は除外していきます。
#上位に来る意味のなさそうな単語を人力削除
forest_meishi <- forest_meishi %>%
filter(! Term %in% c(":","こと","Leader","Children","DeadMan"))さて、あとはぶっちゃけさっきの単語の登場表をもう一度出せば事足りるのですが、なんだかおもしろくないのでグラフィカルな図を作成することにします。
#良い感じの図にする
forest_meishi %>% wordcloud2(size=1,minSize=15)(sizeは描画画面の大きさ、minSizeは値を大きくすると、登場数が少ない単語を表示しなくなる仕様です)
こうすると、このような図が出来上がります。

大きい単語ほど、文章中でよく登場してくる単語です。
兵士や巨人という敵キャラの名前や、ユニやノノという仲間キャラの名前がよく出てくることが確認できますね。
そのほか、毎回のイベントで表示する「危険度が上昇しました」という文章で使われる単語も大きなサイズで現れました。
あとは動詞や形容詞、接続詞などでも同様に実行すればOKです。
テキスト解析の結果
※大きい単語ほどよく使った単語
よく使った名詞
主に出てくるのはキャラクター名とシステムメッセージ(危険度が上昇しました)でした。
ほかによく使っているのは「体」とか「地面」ですね。
体→「肉塊」とか「身」とかにしたり、「脚」など具体的な名称に変更するとよかったかも。
地面→これも「土」とか「大地」とか、工夫の余地がありそう。
よく使った動詞

森の奥に向かって走るという設定なので、やはり「走る」や「進む」が多くなってますね。
「見る」もけっこう使っているようです。「確認する」とか「注視する」とか、「視界に飛び込む」なんて言葉に変えたり、そもそも見た内容そのものを描写するといった工夫ができそうです。
よく使った形容詞

「大きい」「早い」という言葉をよく使っていたようです。
「早い」に関しては「早く先を急がねば」って言葉を次のステージに移動する際の決まり文句的に使ってたのが原因でした。
「大きい」に関しては調べてみたら、大きな音、大きい岩、大きな獲物などと無意識に連発していました。これは一考の余地ありですね。もう少し比喩表現とかも使った方が良かったかも。
よく使った副詞

「少し」「やや」に関しては「危険度が少し上昇しました」みたいなシステムメッセージが原因のようでした。「ふたたび」も次のステージに行く際の決まり文句「ふたたび走り出した」によるものでした。
「しばらく」は「しばらく痙攣していた」「しばらくその場で立ち尽くした」などという表現でよく使っていたみたいです。何か違うニュアンスの言葉に差し替えたほうがよかったかも。
よく使った接続詞

接続詞に関しては「しかし」が多いですね。ほかの人の文章だとどのくらいなんだろうか・・・?
「そして」はあまり意味のない接続詞なので、もっと使う回数を減らそうと思いました。
終わりに
こんな感じで、自分の書いた文章をテキスト解析することで、自分の無意識の癖をあぶりだすことができるようになりました。
よく使う単語に関しては、より適切な表現に差し替えることで文章に深みが増していくはずです。
今後、校正の段階でテキスト解析をしてみて、効果のほどを検証していきたいですね。
余談ですが、「逃げる僕たちと暗黒の森」は日本語テキストだけで5万5千文字でした。
実際はこれに分岐命令やらなんやらを書いていたので、7~8万文字くらいは書いたのかも。大体薄めの文庫本一冊くらいの分量です。
これくらいの量になると、さすがに目だけでチェックするのは難しいので、テキスト解析とかをやる意味が出てきますね。
みなさんがシナリオを書く際の参考にしてもらえれば嬉しいです。